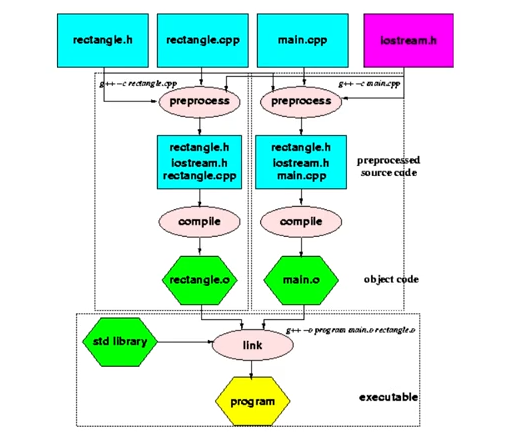
Addressing the issues found in cloud-native applications
Module Outline
1. Spring / Spring IO / Spring Cloud
2. Spring Cloud Netflix
3. Common Concepts
Spring Cloud Origins
1. First, there was the Spring Framework (2004)
- Alternative to low-level JEE approaches
2. Next, Spring sub-projects emerged (2006 - present)
- Spring Security, Web Flow, Integration, Batch, Web Services, XD, Social, Data, Boot, Session, etc.
- Organized under Spring IO umbrella:
Spring Could Subproject
1. "Sub-Umbrella" Project within Spring IO Platform
Goal of Spring Cloud
1. Provide libraries to apply common patterns needed in distributed applications
- Distributed / Versioned / Centralized Configuration Management
- Service Registration and Discovery
- Load Balancing
- Service-to-service Calls
- Circuit Breakers
- Routing
- ....
Where Does NETFLIX Fit Into All of This?
1. Netfliz reinvented itself since early 2007
- Moved from DVD mailing to video-on-demand
* Once USPS largest first-class customer
* Now biggest source of North American Internet traffic in evenings.
2. Became Trailbazers in Cloud Computing
- All Running on Amazon Web Services
3. Chose to publish many general-=user technologies as Open-Source projects
- Proprietary video-streaming technologies are still secret.
Spring and NETFLIX
1. The Spring Team has always been forward looking
- Trying to Focus on Applications of Tomorrow
2. Netflix OSS Mature and Battle-Tested; Why Reinvent?
3. Netflix OSS Not Necessarily Easy and Convernient
- Spring Cloud provides easy interaction
* Dependencies
* Annotations
Spring Cloud Setup
1. Spring Cloud Projects are all based on Spring Boot
- Difficult to employ using only core Spring Framework
- Dependency management based on Boot
- ApplicationContext startup process modified
Server vs. Client
1. "Client" and "Server" are relative terms
- Based on the role in a relationship
- A Microservice is ofter a client and a server
2. Don't get lost on the terminology!
Required Dependenies
1. Replace Spring Boot Parent
- Spring Cloud proejct are based on Spring Boot
org.springframework.cloud
spring-cloud-starter-parent
Angel.SR4
org.springframework.cloud
spring-cloud-start-...
2. ... OR Use Dependency Management Section
org.springframework.cloud
spring-boot-starter-parent
Angel.SR4
pom
import
org.springframework.cloud
spring-boot-starter-...
Summary
1. Spring Cloud is a sub-project within Spring IO Umbrella
- And is itself an umbrella project.
2. Spring Cloud addresses common patterns in distributed computing
3. Spring Cloud enables easy use of Netflix libraries
4. Spring Cloud i based on Spring Boot
Spring Cloud Config
Centralized, versioned configuration management for distributed applications
Objectives
1. At the end of this module, you will be able to
- Explain what Spring Cloud Config is
- Build and Run and spring Cloud Config Server
- Establish a Repository
- Build, Run, and Configure a Client
Module Outline
1. Configuration Management
- Challenges
- Desired Solution
2. Spring Cloud Config
- Server Side
- Client Side
3. Repository Organization
What is Application Configuration?
1. Application are more than just code
- Connections to resources, other applications
2. Usually use external configuration to adjust software behavior
- Where resources are located
- How to connect to the DB
- Etc.
Configuration Options
1. Package configuration files with application
- Requires rebuild, restart
2. Configuration files in common file system
- Unavailable in cloud
3. Use environment variables
- Done differently on different platforms
- Large # of individual variables to manage / duplicate
4. Use a cloud-vendor specific solution
- Coupling application to specific environment
Other Challenges
1. Microservices -> large # of dependent services <--- brittle="" manual="" p="" work="">
2. Dynamic updates
- Changes to services of environment variables require restage of restart <-- activities="" deployment="" p="">
3. Version control <-- p="" traceablity="">
Desired Solution for Configuration
1. Platform / Cloud-Independent solution
- Language-independent too
2. Centralized
- Or a few discrete sources of our choosing
3. Dynamic
- Ability to update settings while an application is running
4. Controllable
- Same SCM choices we use with software
5. Passive
- Services (Applications) should do most of the work themselves by self-registering
Solution:
1. Spring Cloud Config
- Provides centralized, externalized, secured, easy-to-reach source of application configuration
2. Spring Cloud Bus
- Provides simple way to notify clients to config changes
3. Spring Cloud Netflix Eureka
- Service Discovery - Allows applications to register themselves as clients
Spring Cloud Config
1. Designates a centralized server to server-up configuration information
- Configuration itself can be backed by source control
2. Clients connect over HTTP and retrieve their configuration settings
- In addition to their own, internal sources of configuration
Spring Cloud config Server
1. Source available at GitHub:
https://github.com/spring-cloud-samples/configserver
2. Or, it is reasonably easy to build your own
Spring Cloud Config Server _Building, part 1
1. Include minimal dependencies in your POM(or Gradle)
- Spring Cloud Starter Parent
- Spring Cloud Config Server
org.springframework.cloud
spring-cloud-starter-parent
Angel.SR4
org.springframework.cloud
spring-cloud-config-server
Spring Cloud Config Server _ Building, part 2
1. application.yml - indicates location of configuration repository
---
spring:
cloud:
config:
server:
git:
uri: https://github.com/kennyk65/
searchPaths:ConfigData
- ...or application.properties
Spring Cloud Config Server _ Building, part 3
1. Add @EnableConfigServer
@SpringBootApplication
@EnableConfigServer
public class Applicaton{
public static void main(String[] args){
SpringApplication.run(Application.class, args);
}
}
2. That's it!
The Client Side - Building part 1
1. Use the Spring Cloud Starter parent as a Parent POM:
org.springframework.cloouod
spring-cloudstarter-parent
Angel.SR4
2....OR use a Dependency management section:
org.springframework.cloouod
spring-cloud-starter-parent
Angel.SR4
pom
import
The Client Side - Building Part 2
1. Include the Spring Cloud Starter for config:
org.springframework.cloouod
spring-cloud-starter-config
2. Configure application anme and server location in bootstrap.properties / yml
- so it is examined early in the startup process
# bootstrap.properties:
spring.application.name: lucky-word
spring.cloud.config.uri: http://localhost:8001
3. That's it!
- Client connects at startup for additional configuration settings.
EnvironmentRepository - Choices
1. Spring Cloud Config Server uses an
EnvironmentRepository
- Two implementations available: Git and Native (local files)
2. Implement EnvironmentRepository to use other sources.
Environment Repository - Organization
1. Configuration file naming converntion:
-
-.yml
* Or .properties (yml takes precedence)
- spring.application.name = - set by client application's bootstrap.yml(or .properties)
- Profile - Client's spring.profiles.active
* (set various ways)
2. Obtain settings from server:
- http://
://
- String client do this automatically on startup
The Client Side
1. Spring Boot Applications: Include:
- Spring cloud client dependency
org.springframework.cloud
spring-cloud-starter
- Configure application name and server location in bootstrap .properties /yml
* So it is examined early in the startup process
# bootstrap.properties:
spring.application.name:lucky-world
spring.cloud.config.uri: http://localhost:8888
2. That's It!
- Client connects at startup for additional configuration settings.
Environment Repository - Organization Example
1. Assume client application named "lucky-world" and profile set to "northamerica"
- Spring client (automatically) requests
* /luck-word/northamerica
lucky-word-default.yml <-- ignored="" is="" p="" profile="" set=""> lucky-word.yml <-- included="" p="" prededent="" second=""> lucky-word-northamerica.yml <-- first="" included="" p="" precedent=""> lucky-word-europe.yml <-- diffrent="" ignored="" p="" profile="" set=""> lucky-word.properties <-- included="" p="" precedent="" third=""> another-app.yml <-- app="" diffrent="" ignored="" p="">
.yml vs .properties
1. Settings can be stored in either YAML or standard Java properties files
- Both have advantages
- Config server will favor .yml over .properties
# .properties file
spring.config.name=aaa
spring.config.location=bbb
spring.profiles.active=ccc
spring.profiles.include=ddd
# .yml file
-----
spring:
config:
name: aaa
location: bbb
profiles:
active: ccc
include: ddd
Profiles
1. YAML Format can hold multiple profiles in a single file
# lucky-word-east.proerties
luck-word: Clover
# lucky-word-west.properties
luck-word: Rabbit's Foot
# luckyword.yml
---
spring:
profiles: east
lucky-word: Clover
---
spring:
profiles:west
lucky-word: Rabbit's Foot
The Client Side
1. How Properties work in Spring Applications
- Spring apps have an Environment object
- Environment object contains multiple PropertiySources
* Typically populated from environment variables, system properties, JNDI, developer-specified property files, etc.
- Spring Cloud Config Client library simply adds another PropertySource
* By connecting to server over HTTP
* http://
://
- Result: Properties descried by server become part of client application's environment
What about non-Java / non-Spring Clients?
1. Spring Cloud Server exposes properties over simple HTTP interpace
- http://
://
2. Reasonably easy to call server from any application
- Just not as automated as Spring
What if the Config Server is Down?
1. Spring Cloude Config Server should typically run on serveral instances
- So downitme should be a non-issue
2. Clinet application can control policy of how to handle missing config server
- spring.cloud.config.failFast=true
- Deafult is false
3. Config Server settings override local settings
- Strategy: provide local fallback settings.
Spring Cloud Ribbon
1. Understanding and Using Ribbon, The clinet side load balancer
Objectives
1. At the end of this module, you will be able to
- Understand the purpose of Client-Side Load Balancing
- Use Spring Cloud Ribbon to implement Client-Side Load Balancing
What is a Load Balancer?
1. Traditional load balancers are server-side components
- Distribute incoming traffic among serveral servers
- Software (Apache, Nginx, HA Proxy) or Hardware(F5, NSX, BigIP)
Clinet-Side Load Balancer
1. Clinet-Side Load Balancer selects which server to call
- Based on some criteria
- Part of client software
- Server can still employ its own load balancer
Why?
1. Not all servers are the same
- Some may be unavaliable(faults)
- Some may be slower than other (performance)
- Some may be further away than others (regions)
Module Outline
1. Clinet Side Load Balancing
2. Spring Coud Netflix Ribbon
Spring Cloud Netflix Ribbon
1. Ribbon - Another part of the Netflix OSS family
- Clinet side load balancer
- Automatically integrates with service discovery (Eureka)
- Built in failure resiliency (Hystrix)
- Caching / Batching
- Multiple protocols (HTTP, TCP, UDP)
2. Spring Cloud provides an easy API Wrapper for using Ribbon.
Key Ribbon Concepts
1. List of Servers
2. Filtered List of Servers
3. Load Balancer
4. Ping
List of Servers
1. Determines what the list of possible servers are (for a given service (client))
- Static - Populated via configuration
- Dynamic - Populated via Service Discovery ( Eureka )
2. Spring Cloud default - Use Eureka when present on the classpath.
Filtered List of Servers
1. Criteria by which you wish to limit the total list
2. spring Cloud default - Filter servers in the same zone
ping
1. Used to test if the server is up or down
2. Spring Cloud default - delegate to Eureka to determine if server is up or down
Load Balancer
1. The Load Balancer is the actual component that routes the calls to the servers in the filtered list
2. Serveral strategies available, but they usually defer to a Rule component to make the actual decisions
3. Spring Cloud's Default: ZoneAwareLoadBalancer
Rule
1. The Rule is the single module of intelligence that makes the decision on whether to call or not.
2. Spring Cloud's Default: ZoneAvoidanceRule
Using Ribbon with Spring Cloud - part 1
1. Use the Spring Cloud Starter parent as a Parent POM:
org.springframework.cloud
spring-cloud-starter-parent
Angel.SR4
2. ... OR use a Dependency management section:
org.springframework.cloud
spring-cloud-starer-parent
Angel.SR4
pom
import
...exactly the same options as a spring cloud config client or a spring cloud eureka client.
Using Ribbon with Spring Cloud - part 2
1. Include dependency:
org.springframework.cloud
spring-cloud-starter-ribbon
Using Ribbon with Spring Cloud - part 3
1. Low-level technique:
- Access LoadBalancer, use directly:
public class MyClass{
@Autowired LoadBalancerClient loadBalancer;
public void doStuff(){
ServiceInstance instance = loadBalancer.choose("subject");
URI subjectUri = URI.create(String.format("http://$s:%s", instance.getHost(), instance.getPort());
// ... do something with the URI
}
}
API Reference
1. Previous example used Ribbon API directly
2. Not desirable - couples code to Ribbon
3. Upcoming examples will show declarative approach
- Feign, Hystrix.
Customizing
1. Previously we escribed the deaults. What if you wnat to change them?
2. Declare a separate config with replacement bean.
@Configuration
@RibbonClient(name="subject", configuration=SubjecConfig.class)
public class MainConfig{
}
@Configuration
public class SubjectConfig{
@Bean
public IPing ribbonPing(IClientConfig config){
return new PingUri();
}
}
What Customizing Choices are available
1. Quite a Few!
- Recommend looking at the JavaDoc or GitHub Code
Summary
1. Client-Siode Load Balancing augments regular load
balancing by allowing the client to select a server based on some criteria.
2. Spring Cloud Riboon is an easy-to-use implementation of client side load balancing.
Spring Cloud Feign
Declarative REST Client
Objectives
1. At the end of this module, you will be able to
- Call REST services using the Feign libraries
- Understand how Feign, Ribbon, and Eureka collaborate
Module Outline
1. What is Feign
2. How to use Feign
Feign
1. What is it?
- Declarative REST client, from NetFlix
- Allows you to write calls to REST services with no implementation code
- Alternative to Rest Template (even easier!)
- Spring Cloud provides easy wrapper for using Feign
Spring REST Template
1. Spring's Rest Template provides very easy way to call REST services
RestTemplate template = new RestTemplate();
String url = "http://inventoryService/{0}";
Sku sku = template.getForObject(uri, Sku.class, 4724352);
2. Still, this code must be
1) Written
2) Unit-tested with mocks / stubs.
Feign Alternative - Declarative Web Service Clients
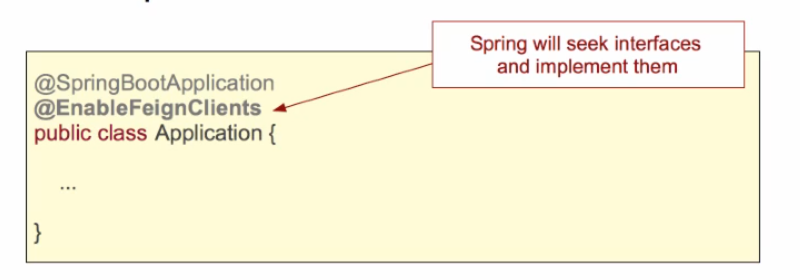
1. How does it work?
- Define interfaces for your REST client code
- Annotate interface with Feign annotation
- Annotate methods with Spring MVC annotations
* Other implementations like JAX/RS pluggable
2. Spring Cloud will impleent it at run-time
- Scans for interfaces
- Automatically implements code to call REST service and process response
Feign Interface
1. Create an Interface, not a Class:
Note: No extra dependencies are needed for Feign when using Spring Cloud.
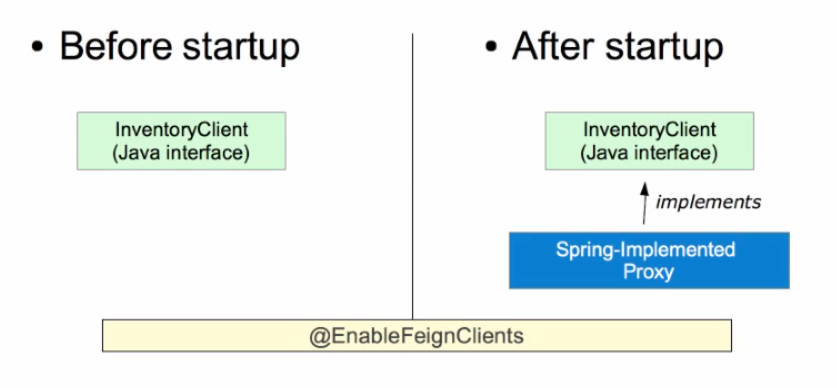
Runtime Implementations
1. Spring scans for @FeignClients
- Provides implementations at runtime
2. That's it!
- Implementations provided by Spring / Feign!
What does @EnableFeignClients do?
You can @Autowire an InventoryClient wherever one is needed
Ribbon and Eureka _ Where do they fit in?
1. The previous example - hard-codeedURL
@FeignClient(url="localhost:8080/warehouse")
2. ...use a Eureka "Client ID" instead:
@FeignCliuent("warehouse")
3. Ribbon is automatically enabled
- Eureka gives our application all "Clients" that match the given Client ID
- Ribbon automatically applies load balancing
- Feign hanldes the code.
Runtime Dependency
1. Feign starter required at runtime:
...but not compile time
org.springframework.cloud
spring-cloud-starter-feign
Summary
1. Feign provides a very easy way to call RESTful services
2. Feign integrates with Ribbon and Eureka automatically.
Spring Cloud Hystrix
Understanding and Applying Client Side Circuit Breakers
Objectives
1. At the end of this module, you will be able to
- Understand how software circuit breakers protect against cascade failure
- Use Spring Cloud Netflix Hystrix annotations within your software to implement circuit breakers
- Establish simple monitoring of Circuit Breakers using Hystrix Dashboard and Turbine
Module Outline
1. Cascading Failures and the Circuit Breaker Solution
2. Using Spring Cloud Netflix Hystrix
3. Monitoring with the Hystrix Dashboard and Turbine
The Problem: Cascading Failure
1. Having a large number of services as dependencies can lead to a 'cascading failures'
2.Without mitigating this, microservices are a recipe for certain disaster!
Distributed Systems - More Failure Opportunities
1. Distributed systems -> more opportunity for failure.
- Remember tghe Fallacies of Distributed Computing.
2. The Math: Assume 99.95% Uptime (Amazon EC2 SLA)
- Single app - 22 minutes down per montjhe
- 30 interrelated services - 11 hours downtime per month ( bad )
- 100 interrelated services - 36 hours downtime per month ( ouich! )
The Circuit Breaker Pattern
1. Consider a household circuit breaker
- It "watches" a circuit
- When failure occurs ( too much current flow ), it "opens" the circuit (disconnects the circuit )
- Once problem is resolved, you can manually "close: the breaker by flipping the switch.
- Prevents cascade failure
* i.e. - your house burning down.
Hystrix - The Software Circuit Breaker
1. Hystrix - Part of Netflix OSS
2. Light, easy-to-use wrapper provided by Spring Cloud.
3. Detects failure conditions and "opens" to disallows further calls
- Hystrix Default - 20 failures in 5 seconds
4. Identify "fallback" - what to do in case of a service dependency failure
- Think: catch block, but more sophisticated
- Fallbacks can be chained
5. Automatically "closes" itself after interval
- Hystrix Default - 5 seconds.
Comparison with Physical Circuit Breaker
Hystrix ( Spring Cloud ) Setup
1. Add the Dependency:
org.springframework.cloud
spring-cloud-starter-hystrix
2. Enable Hystrix within a configuration class:
@SpringBootApplication
@EnableHystrix
public class Application {
}