* You declare a name by saying what kind of thing it is:
const int MaxSize; // declares a constant
extern int v; // declares a variable
void foo (int formalParam); // declares a function(and a formal parameter)
class Bar{...}; // declares a class
typedef Bar* BarPointer; // declares a type name
* In most cases, once you have declared a name, you can write code that uses it. Furthermore, a program may declare the same thing any number of times, as long as it does so consistently. That's why a single header file can be included by several different non-header files that make up a program - header files contain only declarations.
* You define constants, variables, and functions as follows:
const int MaxSize = 1000; // defines a constant
int v; // defines a variable
void foo(int formalParam){++formalParam;} //defines a function
* A definition must be seen by the compiler once and only once in all the compilations that get linked together to form the final program. A definition is itself also a declaration (i.e., if you define something that hasn't been declared yet, that's OK. The definition will serve double duty as declaration and definition.).
* When a non-header file is compiled, we get an object-code file, usually ending in ".o". These are binary files that are "almost" executable - for some variables and function, instead of the actual address of that variable/function; they still have its name. This happens when the variable or function is declared but not defined in that non-header file ( after expansion of #includes by the pre-processor).
* That name will be assigned an address only when a file containing a definition of that name is compiled. And that address will only be recorded in the object code file corresponding to the non-header source file where the name was defined.
* The complete executable program is then produced by linking all the object code files together. The job of the linker is to find. for each name appearing in the object code, the address that was eventually assigned to that name, make the substitution, and produce a true binary executable in which all names have been replaced by addresses.
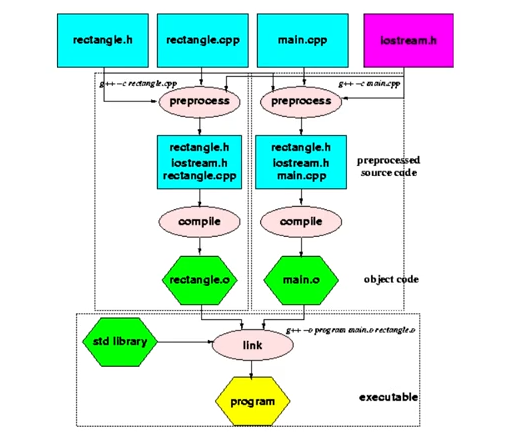
* Understanding this difference and how the entire compilation/build process works (Figure 7.1, "Building 1 program from many files") can help to explain some common but confusingly similar error messages:
If the compiler says that a function is undeclared, it means that you tried to use it before presenting its declaration, or forgot to declare it at all.
* The compiler never complains about definitions, because an apparently missing definition might just be in some other non-header file you are going to compile later. but when you try to produce the executable program by linking all the compiled object code files produced by the compiler, the linker may complain that a symbol is undefined (none of the compiled files provided a definition) or is multiply defined (you provided two definitions for one name, or somehow compiled the same definition into more than one object-code file).
* For example, if you forget a function body, the linker will eventually complain that the function is undefined. If you put a variable or function definition in a .h file and include that file from more than one place, the linker will complain that the name is multiply defined.