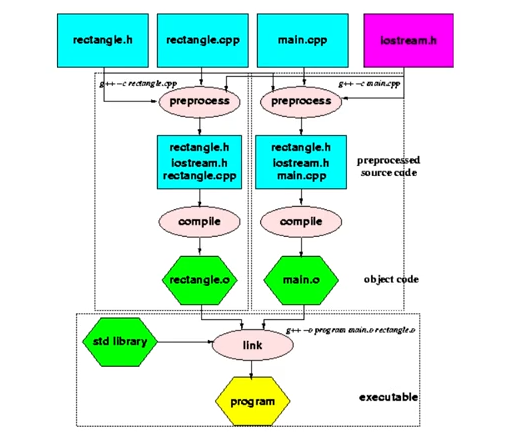
* Splitting the program into pieces like this helps, among other things, divide the responsibility for who can change what and reduces the amount of compilation that must take place after a change to a function body.
* When you have a program consisting of multiple files to be compiled separately, add a -c option to each compilation. This will cause the compiler to generate a .o object code file instead of an executable. Then invoke the compiler on all the .o files together without the -c to link them together and produce an executable:
g++ -g -c file1.cpp
g++ -g -c file2.cpp
g++ -g -c file3.cpp
g++ -g -o programName file1.o file2.o file3.o
* (If there are no other .o files in that directory, the last command can often be abbreviated to "g++ -o programName -g *.o".) The same procedure works for the gcc compiler as well.
Actually, you don't have to type separate compilation commands for each file. You can do the whole thing in one step:
g++ -g -o programName file1.cpp file2.cpp file3.cpp
* But the step-by-step procedure is a good habit to get into. As you begin debugging your code, you are likely to make changes to only one file at a time. If, for example, you find and fix a bug in file2.cpp, you need to only recompile that file and relink:
g++ -g -c file2.cpp
g++ -g -o programName file1.o file2.o file3.o
Use an editor (e.g., emacs) to prepare the follwing files:
hellomain.cpp
#include <iostream>
#include "sayhello.h"
using namespace std;
int main()
{
sayHello();
return 0;
}
sayhello.h
#ifndef SAYHELLO_H
#define SAYHELLO_H
void sayHello();
#endif
sayhello.cpp
#include <iostream>;
#include "sayhello.h"
using namespace std;
void sayHello()
{
count << "hello in 2parts!" << endl;
}
* To compile and run these, give the commands:
g++ -g -c sayhello.cpp
g++ -g -c hellomain.cpp
ls
g++ -g -o hello1 sayhello.o hellomain.o
ls
./hello1
* Note, when you do the first ls, tht the first two g++ invocations created some .o files.
Alternatively, you can compile these in one step. Give the command
rm hello1 *.o
ls
just to clean up after the previous steps, then try compiling this way:
g++ -g -o hello2 hellomain.cpp sayhello.cpp
ls
./hello2
* An even better way to manage multiple source files is to use the make command.
Some Useful Compiler Options
* Another useful option in these compilers is -D. If you add an option -Dname=value, then all occurrences of the identifier name in the program will be replaced by value. This can be useful as a way of customizing programs without editing them. If you use this option without a value, -Dname, then the compiler still notes that name has been "defined". This is useful in conjunction with compiler directive ifdef, which causes certain code to be compiled only if a particular name is defined. For example, many programmers will insert debugging output into their code this way:
...
x= f(x,y,z);
#ifdef DEBUG
cerr << "the value of X is: " << x <<endl;
#endif
y=g(z,x);
...
* The output statement in this code will be ignored by the compiler unless the option -DDEBUG is included in the command line when the compiler is run.[38]
Sometimes your program may need functions from a previously-compiled library. For example, the sqrt and other mathematical functions are kept in the "m" library (the filename is actually libm.a). To add functions from this library to your program, you would use the "-lm" option. (The "m" in "-lm" is the library name.) this is a linkage option, so it goes at the end of the command:
g++ -g -c file1.cpp
g++ -g -c file2.cpp
g++ -g -c file3.cpp
g++ -g -o programName file1.o file2.o file3.o -lm
The general form of gcc/g++ commands is g++ compilation-option files linker-options Here is a summary of the most commonly used options for gcc/g++: