이제 [식 5.2]를 차분히 살펴볼 시간입니다. [식 5.2]는 합성 함수의 미분은 구성 함수들의 미분의 곱으로 분해할 수 있음을 뜻합니다. '곱하는 순서'까지 말해주지는 않지만 사실 어떤 순서로 곱해도 상관없습니다. 그러니 [식 5.3]과 같이 출력에서 입력 방향으로(즉, 역방향으로)순서대로 계산해보겠습니다.
dy/dx = ((dy/dy*dy/db)*db/da)da/dx
[식 5.3]과 같이 출력에서 입력 방향으로, 즉 보통의 계산과는 반대 방향으로 미분을 계산합니다. 이때 [식 5.3]의 흐름은 [그림 5-2]와 같습니다.
[그림 5-2]처럼 y에서 입력 x 방향으로 곱하면서 순서대로 미분하면 최종적으로 dx/dy가 구해집니다. 계산 그래프로는 [그림 5-3]처럼 됩니다.
[그림 5-3]의 계산 그래프를 잘 관찰해봅시다. 우선 dx/dy(=1)에서 시작하여 dy/db와 곱합니다. 여기서 dy/db는 함수 y=C(b)의 미분입니다. 따라서 함수 C의 도함수를 C'의 도함수를 C''로 나타내면dy/db=C''(b)라고 쓸 수 있습니다. 마찬가지로 db/da=B'(a)이고 da/dx=A'(x)입니다. 이에 따라 [그림 5-3]의 계산 그래프는 다음과 같이 단순화할 수 있습니다.
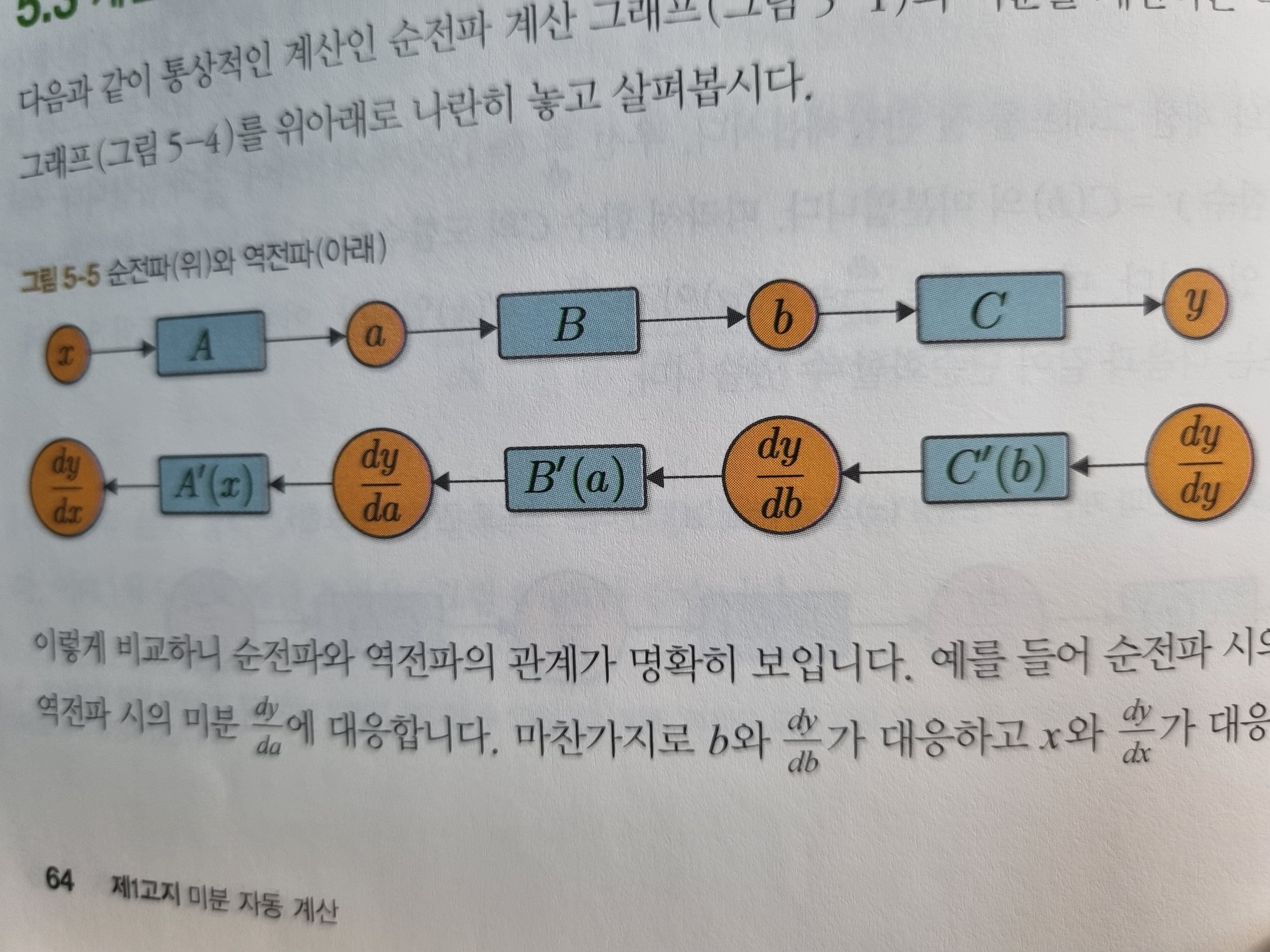
[그림 5-4]와 같이 도함수의 곱을 함수 노드 하나로 그릴 수 있습니다. 이제 미분값이 전파되는 흐름이 평확해집니다. [그림 5-4]를 보면 'y의 각 변수에 대한 미분값'이, 즉 변수 y, b, a, x 에 대한 미분값이 오른쪽에서 왼쪽으로 전파되는 것을 알 수 있습니다. 이것이 역전파입니다. 여기서 중요한 점은 전파되는 데이터는 모두 'y의 미분값'이라는 것입니다. 구체적으로 dy/dy, dy/db, dy/da, dy/dx처럼 모두' y의 oo에 대한 미분값'이 전파되고 있습니다.
[식 5.3]과 같이 계산 순서를 출력에서 입력 방향으로 정한 이유는 y의 미분값을 전파하기 위해서입니다. 즉 y를 '중요 요소'로 대우하기 때문입니다. 만약 입력에서 출력방향으로 계산했다면 중요 요소는 입력인 x가 됩니다. 이 경우 전파되는 값은 dx/dx -> da/dx -> db/dx -> dy/dx가 되어 x 에 대한 미분을 전파하게 됩니다.
머신러닝은 주로 대량의 매개변수를 입력받아서 마지막에 손실 함수(loss function)를 거쳐 출력을 내는 형태로 진행됩니다. 손실 함수의 출력은(많은 경우) 단일한 스칼라값이며, 이 값이 '중요 요소'입니다. 즉, 손실 함수의 각 매개변수에 대한 미분을 계산해야 합니다. 이런 경우 미분값을 출려에서 입력 방향으로 전파하면 한 번의 전파만으로 모든 매개 변수에 대한 미분을 계산할 수 있습니다. 이처럼 계산이 효율적으로 이뤄지기 때문에 미분을 반대 방향으로 전파하는 방식(역전파)을 이용하는 것입니다.