BPR의 향후 전망은 크게 ‘독자 개발 적용 방식’과 ASP 서비스와 같은 ‘위탁 처리방식’으로의 세분화가 정착될 것으로 예상해 볼 수 있다.
그리고 ‘물리적 적용범위’에서 본다면 기존의 BPR이 ‘같은 건물내’에 국한되기도 했던 것에 비해 인터넷과 같은 통신망의 발달에 의해서
‘공간 개념을 넘어선 BPR’을 예상할 수 있다. 이를테면 삼성그룹에서 사용한다는 전용 전산망 ‘싱글’은 전 세계 어느 곳에 있는 삼성 그룹내 회사에서도 동시에 이용이 가능하다고 한다. 또한 이러한 BPR의 공간 개념 탈피는 대기업에만 적용되는 것은 아니다.
2024년 9월 30일 월요일
BPR 기대효과
□ 프로세스 체계로의 접근방법은 미국의 마이클 해머 교수가 1980년대 말에 발표하여 한때 경영자들과 기업에 인기를 모았던 BPR(Business Process Re-engineering) 경영기법이 근본이다.
- BPR 기법의 본래 의도 및 목적은 조직이 자체의 역량을 핵심프로세스에 집중시키기 위해서 비 핵심프로세스와 핵심프로세스를 분석하여 비 핵심프로세스를 핵심프로세스에 집중시킴으로써 기업의 역량을 강화하자는 것이다.
□ 지금까지의 기업들은 조직이 생산한 제품을 고객의 손에 넘기는 데까지 많은 업무 단계와 결재 단계를 거치도록 구조화되어 있다.
- 고객을 목표로 한 과정에서 조직 내의 이해관계로 인해서 고객의 요구사항이 도중에 변질되거나 누락되는 경우가 있다.
□ 그러나 프로세스 체계를 구축한 기업들은 고객의 요구사항들이 고객에게 제공되는 과정에서 핵심프로세스만을 거치는 구조를 확립하게 한다.
- 조직의 집중력으로 유연성과 신속성을 배가시켜 고객의 요구사항을 충분히 충족시킴.
□ 따라서 회사의 프로세스 체계를 구축하는 것은 조직의 미션과 비전, 목적과 세부목표를 명확하게 해준다.
- 조직의 핵심프로세스를 파악하여 프로세스의 상호관계 및 프로세스 목표를 명확히 정하여 운영함.
□ 기업이 분명한 목적을 가지고 품질경영시스템으로 고객만족 프로세스를 구축한다면 고객만족을 넘어 고객감동 달성이 가능하다.
BPR 적용 방법

보통 현업에서 적용하는 방법은 7가지 단계로 요약될수 있습니다
1. 사전준비단계 - 공감대 형성
사전조사에 따른 개선활동에 대한 개념, 방법, 계획을 이해하고 공감대를 갖도록 한다.
2. 개선과제 선정단계
- 업무 프로세스(기업프로세스)를 전체적으로 취합하고 가장 핵심이 되는 프로세스를 선정하여
단시간내에 개선을 통한 가시적 성과를 보여줌으로 조직내 저항을 최소화
3. 현황및 문제점 도출 단계
- 현재의 프로세스구조를 파악하고 맵을 구성(업무롤)
자료수집, 인터뷰, 현행업무 프로세스맵 구성으로 업무를 파악하는게 주요하고 문제점을 도출하여
현업무의 검증을 통해 문제를 확정한다.
- 긴급하게 개선할 필요가 있는사항은 즉시 개선하도록 한다.
4. 벤치마킹 - 평가나 측정 또는 판단을 위해 필요한 기준
문제점에 대해 최고로 인정되는 타기업및 조직의 작업 방법(또는 서비스)을 찾아 최우량 방식을
업무에 적용하여 개선한다.
정량적이고 정성적으로 분석하여 어느정도의 격차가 발생되는지를 분석하여 개선목표를 설정한다.
5. 개선안 도출
개선목표가 나왔음으로 기존의 프로세스맵을 어떤식으로 재구성하여 새로운 프로세스맵을 만들지
생각하여야한다. 개선안에 대해 정형화된 방법이 존재하지 않을수 있음을 생각하여야 한다.
- 프로세스는 최소화 하도록 한다.
- 현업부서와 충분한 커뮤니 케이션이 새로운 프로세스 맵 작성에 도움이 된다.
6. 프로세스의 개선활동 단계
확정된 새로운 프로세스를 개선효과가 큰 순서대로 현업에 적용하기 위해 시뮬레이션을 실시하고
관련부서는 실무에 적용하여 개선내용에 대한 피드백을 하여야 한다.
- 시뮬레이션에 의한 개선예상 효과를 최종 확정한다.
7. 발표및 사후관리
개선된 내용과 향후 적용할 대상에 대한발표를 함으로 조직원이 동참하도록 하여야한다.
실행이 따르지 않는다면 새로운 프로세스맵은 단지 종이조각에 지나지 않는다.
적적용에 따른 안정화 기간동안 개선 적용 내용을 주기적으로 확인하여 과거 상태로 돌아가지 않도록
점검하여야한다.
BPR 적용사례
기업들이 ERP 시스템을 구축하기 위해서는 업무 프로세스 재설계(BPR: Business Process Reengineering) 단계를 반드시 거치게 된다. 이에 업무 프로세스 재설계와 관련하여 ERP 시스템 구축전략은 일반적으로 4가지의 방안 중에서 선택하여 진행된다.
첫째, 기존 업무처리에 따라 ERP 패키지를 수정하는 방안.
둘째, 업무 프로세스 재설계를 실시한 후에 이에 맞도록 ERP 시스템을 구축하는 방안.
(ERP By BPR).
셋째, 업무 프로세스 재설계와 ERP 시스템 구축을 병행하는 방안. (ERP for BPR)
넷째, ERP 패키지에 맞추어 업무 프로세스 재설계를 추진하는 방안. (BPR By ERP)
각각의 방법에는 전체 구축시간, 비용, 컨설팅 능력에 따라서 많은 차이가 있다. 많은 기업들이 업무 프로세스 재설계 실행 후의 업무 프로세스와 ERP 패키지가 제공하는 업무 프로세스를 대응하여 차이(Gap)분석을 통해 ERP 시스템을 구축한다. 이런 경우에는 업무 프로세스 재설계 단계의 프로세스와 ERP 패키지의 프로세스의 차이(Gap)분석 시에 다시 정의된 프로세스를 분석해야 하는 경우가 발생할 수 있어 시스템 구축기간이 길어질 수 있는 단점이 있다. 그리고 ERP 패키지에 맞추어 업무 재설계를 추진하는 경우에는 이미 ERP 패키지가 선진업무 프로세스를 기초로 해 프로그램화 된 것이기 때문에 현 업무 프로세스를 ERP 패키지의 프로세스로 재설계하는 효과를 얻는다. 그러나 때로는 자사에 맞지 않는 프로세스가 발생하기도 한다.
최근에는 ERP 패키지 도입과 업무 프로세스 재설계를 동시에 수행하는 경향이 많다. 이렇게 함으로써 업무 프로세스 재설계 후의 프로세스와 ERP 모듈과의 적합도 분석 작업을 병행하여 차이(Gap)를 최소화할 수 있다. 또한 업무 프로세스 재설계를 ERP 시스템 구축단계 중 모듈분석(Analysis), 설계(Design)단계와 동시에 진행하여 전사적 시스템 구축기간이 단축된다는 장점도 있다. KBS 또한 이러한 ERP 시스템 구축 방안을 선택함으로써 시스템 구축기간을 획기적으로 단축하는 효과가 있었다.
ERP, PI 와 BPR 관계

BPR(Business Process Reengineering, 기업경영혁신)과 ERP(Enterprise Resources Planning, 기업자원계획)과는 연관이 있습니다.
ERP는 BPR을 하기 위한 수단 중 하나라고 말씀드릴 수 있겠습니다.
ERP(Enterprise Resource Planning)에는 선진 기업들의 최고 업무 절차(Best practice) 가 내장되어 있어서 ERP를 도입하여 업무에 적용하면 BPR(Business Process Reengineering)이 저절로 수행되는 효과를 기대할 수 있습니다.
하지만 많은 기업들은 ERP를 도입하기 위해 먼저 프로세스 개선(PI, Process Improvement)을 진행하고 ERP를 도입함으로써 도입 및 적응 기간을 줄이려는 노력을 기울일 수 있습니다.
여기서 주의할 것은 국내에서 개발한 대부분의 ERP는 회계, 영업관리, 자재관리, 인사관리 등 흔히 기간업무를 컴퓨터로 처리하기 위한 응용소프트웨어 패키지를 연동시킨 수준의 S/W로 진정한 의미의 ERP가 아니기 때문에 국내에서 개발된 ERP를 도입할 때는 BPR을 기대하기 힘듭니다.
SAP이나 Oracle Application, BAAN 등 Best Practice가 내장되어 있는 ERP를 도입하면서 프로세스 혁신(PI) 컨설팅을 동시에 받아야 BPR효과가 있습니다.
ERP가 무엇인지 한줄로 설명한다면 기업의 모든 자원의 흐름을 어느 한순간, 어느 한곳이라도 언제든지 정확히 추출해 내어 자원의 효율적인 배치를 평가하는 것이 긍국적인 목적이며 이 외에도 회계적인 자료라던지 등을 통해 기업의 업무를 극대화 시킬수 있는 전략적인 도구라 하겠습니다.
ERP를 구축하기 위해서는 많은 인력과 노력, 부서간의 협력 및 직원들과 임원의 참여가 승패를 가린다고 하겠습니다. 또한 구축기간도 최소 1년에서 길게는 수년이 걸리며 일단 초기 모델이 완성된다고 하더라도 철저한 유지관리가 요구됩니다.
일단 ERP가 성공적으로 구축되어 필요한 자료가 추출되면 기업의 장접과 약점을 가려나가야 합니다.
기업목적과 목표, 시장의 흐름과 영향요소, 경쟁성 분석 등 여러가지의 분석자료와 ERP 자료를 바탕으로 이제 BPR을 통해 기업의 혁신이 이루어 져야 하는 것입니다. 장점은 강화하고 약점은 과함히 버리던지 축소시키며 기업의 경쟁성을 키워 나가는 것이지요.
ERP와 BPR은 하루아침에 이루어 지는 것이 아닙니다. 꾸준한 노력과 투명한 경영, 그리고 모든 직원이 하나가 되어 장기적인 투자를 하지 않고서는 결코 이루어지지 않고 결국엔 다른 또 하나의 필요없거나 버려진 도구로밖에 전락하게 되기 쉽기 때문입니다
BPR의 목표
BPR은 기업활동을 부가가치의 창조를 위한 프로세스로 파악하는 것이며 이 프로세스란 고객의 주문부터 제품의 인도까지 이익을 실현하는데 핵심이 되는 활동들의 연결고리를 말한다. 기업은 모든 조직 및 활동을 이 프로세스에 집중시키기 위해 불필 요한 부분을 모두 제거, 기업의 효율을 극대화시킨다는 것이 BPR의 목표가 되고 있다.
BPR에서 말하는 프로세서란 개인이나 특정부서의 업무가 아니고 여러 부서간에 수행되고 있는 프로세스(Process)이다. 여기 에서 말하는 프로세스란 “내부 또는 외부의 고객을 위하여 유용한 제품이나 서비스를 전달하기 위하여 반복적이며 측정가능한 과업(Task)의 연 결”을 의미한다.
즉, 조직 내의 연계된 프로세스를 고객입장에서 서서 경쟁자보다 월등한 성과를 내야 한다는 관점의 변화를 요구한다. 고객들은 자신이 원하는 가격의 제품이 원하는 시간에 원하는 품질로 원하는 서비스에 의해 제공되는가에 관심이 있지, 어떤 부서들이 어떤 과정을 거쳐 일을 하는가에는 전혀 관심이 없다.
따라서 비지니스 리엔지니어링은 내부 또는 외부의 고객요구사항을 접수하여 최종적으로 전달되는 일련의 과정을 하나의 프로세스로 설정하여, 경쟁사보다 월등한 성과를 내기 위해 시도하는 프로세스 혁신운동이라고 할 수 있다.
BPR 개념
"할 수 있는 것"에서 "해야하는 것"으로의 혁신적인 사고 전환을 통해 회사 업무 처리 프로세서를 목적추구형, 병렬처리형 등으로 혁신시킴은 물론 이와 관련된 Infrastructure 및 Technology, Organization을 동시 에 혁신 시켜 기업의 경쟁력을 세계 초일류 수준으로 끌어올리는 기법이다.

Fundamental(기본적인)
먼저 기업이 무엇을 해야 할지를 결정하고, 그 다음 그것을 어떻게 할지를 결정한다.
리엔지니어링에서는 아무것도 당연한 것으로 여기지 않는다. 리엔지니어링에서는 '지금 있는'것을 무시하고, '반드시 있어야 할'것에 집중한다.
Radical(근본적인)
리엔지니어링에서 근본적인 재설계는 현존하는 모든 구조와 절차를 버리고, 완전히 새로운 업무처리 방법을 만들어 내는 것을 의미한다. 리엔지니어링은 업무를 개선시키거나 향상시키거나 또는 변경시키는 것이 아니라 다시 만들어내는 것이다.
Dramatic(극적인)
리엔지니어링은 오직 확실한 개혁이 필요한 때에만 사용해야 한다. 점진적인 개선은 미세 조정을 필요로 하지만, 극적인 개선은 낡은 것을 날려버리고 새로운 어떤 것으로 대체 해야만 이룰 수 있다.
Processes(프로세스)
대부분의 기업인들은'프로세스 지향적'이지 않다. 그들은 프로세스가 아니라 과엽, 직무, 사람, 구조들에 초점을 맞추고 있다. 리엔지니어링에서는, 업무 프로세스를 '하나 이상의 입력(input)을 받아들여 고객에게 가치잇는 결과(output)를 산출하는 행동의 집합'으로 정의한다
BPR의 등장배경
단어의 뜻에서 알수 있듯 BPR(Business Process Reengineering)은 ‘기업의 업무 프로세스를 혁명적으로 고치자’는 것을 의미한다.
쉽게 말해, 회사에서 벌어지는 모든 일들의 처리과정을 A에서 Z까지 한꺼번에 고쳐서 그 개선효과를 극대화하자는 의미이다.
BPR의 등장배경은 ‘미통일된 기업업무 처리방식의 혼선 때문’이라고 보면 된다. 말은 이렇게 하지만 ‘컴퓨터가 기업의 업무처리에
도입되면서부터’ 누적되기 시작한 ‘업무의 중복 및 혼선’이 BPR의 등장배경이라고 보는 것이 맞다.
더 쉽게 설명을 하자면 불과 2, 30여년 전만 하더라도 우리 나라는 말할 것도 없고 미국의 기업에서 조차 ‘타자기’를 사용하는 구닥다리
업무방식이 전부였다. 종이 서류에 내용을 적어서 상급자에게 결재를 올리고 최종단계에서 사장이 싸인을 하면 다시 아래로 전달이 되어 실제로 일이 진행이 되는 그런 ‘단계’를 거쳐야 했다는 말이다. 하지만 컴퓨터가 회사의 업무에 도입되면서 회사원들의 일이 매우 간편해지기 시작했다.
그래서 기업들은 앞을 다투어 ‘업무 전산화’에 나서게 되었다. 불행히도 거기에서부터 BPR의 필요성이 싹을 트게 된다. 기업 내부에서도
부서별로 사용하는 컴퓨터 체제가 다른 경우들이 나타나게 된 것입니다. 예를 들면 전산실에서는 유닉스, 비서실에서는 도스, 영업부에서는 매킨토쉬 등을 사용하는 그런 경우가 된다. 문제는 이들 각각의 컴퓨터 시스템은 매우 훌륭하지만 ‘호환성이 떨어진다’는 결정적인 약점이 드러나기 시작했던
것이다.
이를테면 2003년 10월 전산실과 영업부의 보고서를 취합해서 갖고 오라는 사장의 지시가 떨어졌을 때, 문제가 복잡해 진다는 얘기가 된다.
유닉스 문서와 매킨토쉬 문서를 도스 환경에서 재작업을 해야하는 문제점이 나타나게된 것이다. 편리하자고 들여놓은 컴퓨터가 오히려 업무를 더디게 만들어 버린 역설에 빠진 것이다. 그래서 ‘이래서는 안되겠다. 업무효과를 향상시키자고 들여온 컴퓨터 때문에 문제가 생겼으니 기업 전산 시스템을 통일시켜 이 참에 아예 업무 처리 과정 자체를 뜯어고치자’는 움직이 나왔고 그것을 ‘BPR’이라고 부르게 된 것이다.
BPM과 자동화의 차이점
BPM(Business Process Management)과 자동화는 비즈니스 프로세스 개선과 효율성 향상을 위한 다른 개념이며 상호 보완적인 역할을 합니다. BPM은 앞서 살펴 본 것과 같이 비즈니스 프로세스 관리의 약자로, 엔드 투 엔드 비즈니스 프로세스를 모델링, 분석 및 최적화하는 방법론입니다.
BPM은 고객의 요구에 맞춰 프로세스를 개선하고 효율성을 높이기 위한 과정으로 이를 통해 기업은 프로세스의 흐름과 복잡성을 이해하고, 비효율성을 개선하며, 고객의 요구에 더욱 빠르고 정확하게 대응할 수 있습니다.
자동화는 소프트웨어나 기술을 사용하여 작업이 자동으로 수행되도록 만드는 것을 의미합니다. 자동화는 비즈니스의 효율성을 높이기 위해 태스크를 자동으로 수행하여 비용, 복잡성, 오류를 감소시키고 작업의 속도와 정확성을 향상시키는 구현 방식입니다. 자동화는 주로 반복적이거나 예측 가능한 작업을 대상으로 하며, 사람의 개입을 최소화하고 자동화된 시스템 또는 소프트웨어를 활용합니다.
BPM과 자동화는 서로 보완적인 관계를 갖습니다. BPM은 비즈니스 프로세스를 모델링, 분석하고 최적화하는데 사용되며, 이를 통해 개선된 프로세스에 대한 가이드라인을 제공합니다. 자동화는 이러한 개선된 프로세스를 구현하는 도구로 사용될 수 있습니다.
BPM 소프트웨어와 자동화 기술을 결합하면 프로세스 개선 사항을 구현하고, 반복적인 작업을 자동으로 수행함으로써 효율성을 극대화할 수 있는데 예를 들어, BPM을 통해 프로세스를 분석하고 개선한 후, 자동화 기술을 활용하여 반복적인 태스크를 자동으로 수행하는 시스템을 구축할 수 있습니다. 이는 비즈니스는 프로세스의 효율성과 정확성을 높이며 더욱 효과적으로 고객 요구에 대응할 수 있게 도와줍니다.
BPM의 장점
비즈니스 프로세스 관리(BPM)는 비효율적이고 반복적인 수동 작업을 자동화하거나 단순화함으로써 다양한 이점을 제공하는데 그 이점들은 다음과 같습니다.
- 비용 절감: BPM은 수작업에 소요되는 인력, 시간 및 자원을 줄여 비용을 절감할 수 있습니다. 프로세스 자동화와 최적화는 불필요한 작업을 제거하고 효율성을 극대화함으로써 비용을 최소화할 수 있습니다.
- 생산성 향상: BPM은 프로세스를 빠르고 정확하게 수행할 수 있도록 최적화합니다. 오류와 지연을 줄이고 작업의 효율성을 높이는 데에 도움을 줍니다. 이는 직원들의 작업 만족도를 향상시키고 창의성을 높여 생산성을 향상시킬 수 있습니다.
- 고객 만족도 증대: BPM은 제품이나 서비스의 품질과 신뢰성을 향상시켜 고객의 만족도를 높일 수 있습니다. 프로세스를 통해 고객의 요구사항과 기대에 부응하거나 초과할 수 있으며, 효율적이고 정확한 서비스 제공으로 고객의 신뢰를 얻을 수 있습니다.
- 수익 증대: 비용 절감과 생산성 향상은 수익을 늘리는 데에 기여합니다. 비즈니스 프로세스의 효율성 향상으로 인해 더 많은 작업을 처리할 수 있으며, 이는 비즈니스 성과와 수익 증대로 이어질 수 있습니다. 또한, 고객 만족도의 향상은 재구매율과 추천율을 높일 수 있어 추가적인 수익을 창출할 수 있습니다.
- 경쟁력 강화: BPM은 차별화된 가치를 제공함으로써 기업의 경쟁력을 강화할 수 있습니다. 프로세스의 효율성과 품질 개선은 고객들에게 더 나은 경험을 제공하고, 기업이 시장의 변화에 신속하게 대응할 수 있는 유연성을 제공합니다.
또한, 혁신적인 비즈니스 모델의 개발을 가능하게 하여 새로운 시장 기회와 동향에 대한 대응력을 강화할 수 있습니다. BPM은 기업이 경쟁력을 유지하고 성장할 수 있는 중요한 요소입니다.
종합하면 비즈니스 프로세스 관리(BPM)는 비용 절감, 생산성 향상, 고객 만족도 증대, 수익 증대, 경쟁력 강화 등 다양한 이점을 제공하며 프로세스 자동화와 최적화를 통해 효율성을 극대화하고 비즈니스 성과를 향상시킬 수 있습니다.
BPM의 핵심 단계
1. 프로세스 모델링
프로세스 모델링은 BPM에서 사용되는 방법으로, 비즈니스 프로세스를 시각적으로 나타내는 모델링 도구를 활용하여 설계하고 문서화하는 과정입니다. 이를 통해 프로세스의 구조와 흐름을 명확하게 이해하고 전달할 수 있으며 프로세스 모델링은 다양한 도구와 표기법을 활용하여 표현합니다.
대표적으로는 플로우차트와 BPMN(Business Process Model and Notation)이 사용되는데 플로우차트는 간단한 기호와 화살표를 사용하여 프로세스의 단계와 결정 흐름을 나타내고 프로세스의 단계적인 진행과 조건에 따른 분기 등을 시각적으로 표현할 수 있습니다.
그에 반해 BPMN은 더 구조화된 방식으로 프로세스를 모델링하는 표기법입니다. 이는 프로세스의 시작과 끝, 작업 흐름, 의사 결정 포인트, 이벤트 등을 그래픽 요소로 표현하며, 프로세스의 구조와 동작을 상세히 기술할 수 있습니다.
BPMN은 각각의 요소와 관계를 정의하는 명확한 규칙을 가지고 있어 다양한 이해 관계자들 간의 의사소통과 프로세스 분석에 도움을 주며 프로세스 모델링은 프로세스의 단계, 작업 흐름, 의사 결정 점 등을 시각화하여 비즈니스 프로세스를 명확하게 설명하고 문서화하는 역할을 합니다.
이를 통해 프로세스 참여자들은 프로세스의 흐름과 역할을 이해하고, 프로세스 개선 및 변경을 위한 기반을 마련할 수 있습니다. 또한 모델링된 프로세스는 이후의 분석, 최적화, 자동화 과정에서 활용될 수 있습니다.
2. 프로세스 실행
프로세스 실행은 BPM에서 중요한 단계로, 실행 엔진 또는 워크플로우 엔진을 활용하여 프로세스를 실행하는 과정을 의미합니다. 이 엔진은 프로세스에 따라 작업을 자동으로 할당하고, 작업의 진행 상황을 모니터링하며, 예외 상황을 처리하고, 다음 단계로의 전이를 관리하는 역할을 수행하며 실행 엔진은 프로세스의 정의에 따라 작업을 할당합니다.프로세스의 각 단계 또는 태스크를 수행할 수 있는 적절한 사람 또는 시스템에게 작업이 자동으로 배정되고, 작업 할당은 조직의 역할과 권한, 우선순위, 가용성 등을 고려하여 이루어집니다.
실행 엔진은 작업의 진행 상황을 실시간으로 모니터링하여 프로세스 참여자와 관리자는 현재 진행 중인 작업의 상태를 파악하고 필요한 조치를 취할 수 있는데 모니터링은 일반적으로 대시보드 또는 작업 목록을 통해 시각적으로 제공됩니다.
그리고 예외 상황은 실행 엔진이 처리해야 할 중요한 부분입니다. 예를 들어, 작업의 지연, 오류 발생, 결재 반려 등과 같은 예외 상황이 발생할 수 있는데 실행 엔진은 이러한 예외를 감지하고 적절한 조치를 취하여 프로세스의 원활한 진행을 보장하게 됩니다. 예외 처리는 자동화된 규칙 또는 사용자의 개입에 따라 이루어질 수 있습니다.
마지막으로 실행 엔진은 프로세스의 다음 단계로의 전이를 관리합니다. 즉, 이전 단계가 완료되면 다음 단계로 자동으로 이동하도록 제어하는데 이를 통해 프로세스의 흐름이 원활하게 유지되며 참여자들은 다음 작업에 대한 알림을 받고 진행할 수 있습니다.
3. 프로세스 모니터링
프로세스 모니터링은 실행 중인 프로세스의 상태를 실시간으로 추적하고 분석하여 조직에 유용한 정보를 제공하는 것을 말하는데 이를 통해 조직은 프로세스의 진행 상황과 성능 지표를 측정할 수 있습니다.
프로세스 모니터링은 실시간으로 프로세스의 상태를 확인하는 기능을 제공하는데 이는 프로세스가 진행되는 동안 어떤 작업이 수행되고 있는지, 각 단계에서 어떤 리소스가 사용되고 있는지, 현재까지 완료된 작업의 비율 등을 실시간으로 파악 가능하게 해, 조직이 프로세스의 진행 상황을 모니터링 및 관리할 수 있도록 해줍니다.
또한 프로세스 모니터링은 성능 지표를 측정하는 데에도 도움을 주는데, 예를 들어 프로세스의 처리 시간, 작업 완료까지 걸리는 시간, 각 단계의 수행 시간 등을 측정하여 프로세스의 효율성을 평가할 수 있습니다. 이를 통해 조직은 프로세스의 병목 현상이나 비효율성을 식별하고 개선할 수 있습니다.
4. 프로세스 최적화
프로세스 최적화는 프로세스 분석과 개선을 통해 조직의 효율성을 향상시킵니다. BPM은 데이터와 성능 지표를 분석하여 프로세스에서 발생하는 병목 현상을 식별하고, 작업 흐름을 개선하며, 자동화와 자동화 기술을 도입하여 프로세스를 최적화하는데 도움을 줍니다.
프로세스 최적화를 위해 BPM은 데이터와 성능 지표를 분석하는데 이를 통해 조직은 프로세스 실행 중에 발생하는 병목 현상, 지연, 비효율성 등을 식별할 수 있습니다. 예를 들어, 작업이 너무 오래 걸리는 단계나 자주 발생하는 작업 중단, 리소스 부족 등을 식별하여 문제를 해결하고 프로세스의 효율성을 향상시킬 수 있습니다.
또한 BPM은 작업 흐름을 개선하는 데에도 도움을 줍니다. 프로세스의 각 단계와 작업을 분석하여 최적화할 수 있는 방안을 찾고, 중복 작업을 줄이거나 작업의 순서를 재조정함으로써 프로세스의 흐름을 개선할 수 있는데, 이는 작업의 효율성을 향상시키고 시간과 비용을 절감할 수 있도록 해줍니다.
BPM은 자동화와 자동화 기술을 도입하여 프로세스를 효율적으로 실행할 수 있도록 지원하는데 반복적이고 규칙적인 작업을 자동화하거나 인공지능 기술을 활용하여 의사 결정을 자동화함으로써 인력을 절감하고 오류 가능성을 줄일 수 있습니다. 조직은 프로세스를 보다 효율적으로 실행할 수 있고 업무 처리 속도와 정확성을 향상시킬 수 있습니다.
BPM(Business Process Management)이란
비즈니스 프로세스 관리(Business Process Management, BPM)는 조직 내의 비즈니스 프로세스를 관리, 개선 및 최적화하기 위한 접근 방법입니다. BPM은 프로세스의 효율성, 품질, 일관성 및 유연성을 향상시키며 조직의 전략적 목표를 달성하는 데 도움을 줍니다
BPM은 다양한 이점을 제공하는데 BPM을 통해 조직은 비즈니스 프로세스의 효율성과 일관성을 향상시키고 비용과 시간을 절감하며 고객 만족도를 향상시킬 수 있습니다. 또한 조직의 유연성과 대응력을 향상시켜 변화하는 비즈니스 요구에 대응할 수 있는 능력을 강화합니다.
즉, BPM은 조직의 프로세스를 효율적으로 관리하고 최적화하여 비즈니스 성과와 경쟁력을 향상시키는 전략적인 접근 방법입니다. 조직은 비용 절감, 생산성 향상, 혁신 추진, 법적인 준수, 지속적인 개선과 성장 등 다양한 이점을 얻을 수 있습니다.
2024년 9월 29일 일요일
ITSM (Information Technology Service Management)
서비스를 이용하는 고객과 서비스 제공자 간에 서비스 수준을 협의하여 그 수준에 맞게 품질을 유지하도록 하는 IT 서비스 관리 기법
고품질의 IT서비스 지원 및 구현을 위한 각 프로세스, 조직, 기술제공 프레임워크II. ITSM의 4가지 관점 및 참조모델
ITSM의 목적
- ITIL기반의 IT 서비스 관리체계 와 운영방식 도입을 의미
- 궁극적 도입효과는 IT 역량과 성숙도 향샹을 통한 비즈니스 가치 제공임
II. ITSM Framework 및 구성요소
- ITSM의 Framework
- ITIL, SLM, eSCM, CMMi의 상호연동을 통한 IT 품질향상나. ITSM Framework의 구성요소
유형
항목
내용
ITIL
정의
IT서비스 관리에 대한 사실상의 산업표준(de-facto standards)
ITSM을 위한 Best Practice를 일관성 있고, 포괄적으로 문서화한 책
구성
서비스 전략, 서비스 설계, 서비스 운영 전환, 서비스 운영, 지속적인 서비스 개선
eSCM
정의
아웃소싱 제공업자의 능력수준을 평가할 수 있도록 만든 모델
구성
조직관리, 인원, 사업, 기술, 지식경영
SLA
정의
공급자와 고객간에 핵심서비스 목표를 정의하고 상호 책임 사항에 대해 협의하여 작성된 문서
구성
Service Catalog, SLA, OLA, Service Quality Plan, Service Report, SLM엔진
CMMI
정의
Capability Maturity Model Integration
시스템공학과 소프트웨어 공학의 기능적 통합에 중점을 두고 있으며, 통합된 제품을 개발, 기반을 제공하기 위한 능력 및 성숙도에 대한 평가와 지속적인 품질 개선 모델
구성
P-CMM, SA-CMM, SE-CMM, IPD-CMM
측정유형: Staged, Continuous Representative Model
프로세스, 프로젝트 관리 등의 25개 process area

Ⅲ. ITSM의 구성도 및 구성요소
가. ITSM의 구성도

- People, Process, Technology, Organization의 유기적 연계를 통하여 최적의 비용으로 고객과 합의된 서비스 품질을 제공할 수 있는 IT운영관리 체계
나. ITSM의 구성요소
구성요소
설 명
프로세스
(Process)
서비스를 계획, 개발 및 적용할 수 있도록 체계적인 지원 및 관리 절차 제공
인력
(People)
인력 개발 및 프로세스 중심적인 조직 구성을 통해 새로운 서비스를 창출하는 인적 자원 관리
기술
(Technology)
프로세스 자동화, 서비스 제공 및 모니터링, 리포팅 하는 기술 솔루션 및 아키텍처
조직
(Organization)
IT에 영향을 끼치는 내/외부의 비즈니스적인 요소 및 문화
- People, Process, Technology, Organization의 유기적 연계를 통하여 최적의 비용으로 고객과 합의된 서비스 품질을 제공할 수 있는 IT운영관리 체계
다. ITTL과 ITSM과의 관계

라. 전통적인 IT운영과 ITSM의 비교
구분
전통적인 IT운영
ITSM
관리관점
IT내부 운영조직 중심
비즈니스 현업 중심
문제해결
Fire Fighting, Reactive
Preventive, Proactive
절차
Informal
Formal Best Practices
관리도구
SMS, NMS etc
Process Enabling Tool
Billing
IT 요소별 사용료 개념
서비스 수준에 따른 과금
Ⅳ. ITIL기반의 ITSM 도입 전략
가. ITSM의 최상의 방식을 모은 문서집, ITIL의 특징
1) Business Requirement를 위한 IT Service 배치
2) IT서비스의 제공 및 관리를 위한 Best Practice 모음
3) IT서비스 제공 및 관리에 대한 벤더에 종속적이지 않은 포괄적이면서도 공개적인 가이드
나. ITSM 도입을 위한 ITIL의 역할
1) SI업체들을 중심으로 자사의 SM 및 아웃소싱 방법론 체계를 구축하는 기반 방법론으로서의 역할
2) 구체적인 실체를 제공하여, 운영업무 전반에 적용 가능한 유효성 제공
3) ITIL을 참조한 지속적인 IT운영 프로세스의 개선 및 구동으로 IT 생산성 향상과 IT 품질개선
다. ITSM 도입전략 Flow
- 참조모델을 통해 ITSM 변화요인을 종합적으로 통제, 실행 기준으로 활용
구분
기대효과
비즈니스 관점
재무적 관점
조직적 관점


- 현재는 주로 IT인프라 중심으로 구축되고 있지만 장기적으로는 ITAM과 거버넌스 측면에서 인프라와 애플리케이션을 통합하는 ITSM으로 발전 예상
3) 소프트웨어의 품질보증 기준으로 널리 사용하는 CMMi을 통한 ITIL이 ITSM을 위한 업계 표준으로 널리 인정받는 시장 현황 "끝"
cf1. CMDB(Configuration Management Database)
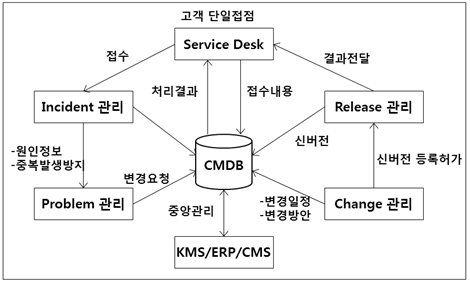
항목
설명
Configuration 정보
- HW,NW,SW 자산내역, IT인프라 관계정보
Incident 정보
- Incident별 중요도, 요청고객정보, 처리현황
Problem 정보
- 관련 Incident ID, 과거 유사사례, 처리방안
Change 정보
- 서비스 변경이력, 변경내용, 변경사유
Service 정보
- 서비스ID, 서비스 접수채널, 접수담당자
나. CMDB 활용방안
- 오류사항간의 선별분류 시간(Triage time)의 획기적 감소I. IT 아웃소싱 서비스의 계약 기간 전체 단계를 커버하는 품질 모델, e-SCM의 개요
가. eSCM(e-Sourcing Capability Model)의 개요
- 아웃소싱 전체 절차에 관한 93개 Best Practice를 체계화하여 업무개선 지침으로 활용하고, 제공업자의 능력수준을 평가할 수 있도록 만든 모델
- IT 아웃소싱 관계 실패율이 2년내 20~25%, 5년내 50%이며, 실패요인으로는 정의된 서비스 목표의 부재, IT 아웃소싱 프로세스 전반에 걸친 미흡한 활동
- IT 서비스 제공자와 고객간의 계약 전체 단계를 커버하는 품질 모델의 부재
- 고객이 소싱 서비스 공급자의 능력을 평가할 객관적인 수단을 제공

항목 | 내용 및 특징 |
조직관리 | - 조직의 지도층은 의사소통 및 고객관리뿐만 아니라 효과적인 관리를 위한 시스템 필요 - 조직관리체계 수립, 성과측정 및 관리, 고객관계수립: 리더, 팀조성자, 이행자로구성 |
인원 | - 기술습득, 능력개발, 동기부여 및 지속. - 서비스 능력 및 품질을 결정하는 핵심요소 |
사업 | - 요구사항 이해, 양질 서비스 제공, 서비스 수준 지속적인 개선, 절차 및 문서화 |
기술 | - IT 소싱 서비스 업계에서 서비스 설계, 개발, 공급의 수단으로서 중요한 역할 |
지식경영 | - 공급자가 목표달성을 위해 포괄적으로 지식을 수집, 체계화, 정리, 분석하여 배포 |
레벨
프랙티스#
설명
5
우수성 유지
-
- 레벨 2, 3, 4 의 모든 프랙티스를 이행하고 일정기간 인중 평가 기간 유지
4
혁신을 통한 발전
11
고객의 요구사항을 만족시키고자 자사의 능력을 지속적으로 향샹할 수 있음 성과 예측 가능함.
3
측정을 통한 관리
31
공급자의 활동을 객관적으로 측정 및 관리할 수 있음 고객의 요구 사항에 적합한 서비스가 자사의 경험에 크게 다른 경우에도 해당서비스를 공수 할 수 있음.
2
고객요구사항이행
51
서비스 공급자는 요구사항을 파악하고 고객과의 약정에 따라 서비스를 공급하는 절차를 공식화 - 고객기대수준에 적합한 서비스면 기대 수준 맞춤
1
최초 단계
공식적인 시스템 및 절차 없이 운영됨
절차가 있더라도 엄격 준수 이행 안함.
- 93개의 프로틱스 유형: 정책, 절차, 지침프로세스, 기타프로세스
IV. ITIL을 기반으로 하는 ISO 20000과 eSCM의 비교
구 분
ISO 20000 (BS15000)
eSCM
개념
IT서비스의 Best Practice를 정립 하기 위한 ITIL에 기반한 국제 표준 인증규격
- 제공업자의 능력수준을 평가할 수 있도록 만든 모델 (Capability)
특징(용도]
고객의 요구사항을 만족하는 IT 서비스를 개발하고 구현할 수 있는 방법제공, 표준 제공
IT 서비스에 대한 비용관점의 효과성(effectiveness)를 평가
고객이 서비스 공급자의 능력을 평가할 객관 적인 수단을 제공함
ITO의 전단계에 걸쳐, 고객만족을 절대 우선의 목표로 선정
세부 내용
- Part I: 서비스 관리를 위한 인증 규격(Specification)
- Part II: 서비스 관리를 위한 실행 지침(Code of Practice]
프로세스 영역(Process Area]
조직관리, 인력, 사업, 기술, 지식경영에 대한 capability level 평가
- eSCM의 레벨(최고측혁우]
현황
영국표준에서(BS->ISO] 국제 표준 으로 격상됨에 따라 공공기관 도입 필요성 증가
eSCM2.0에서 ITIL 수용
LG CNS Level4 획득
인증기관
- 영국표준협회 -> ISO 변경
CMU(카네기 멜론 대학]: 미국
MSP 서비스
1. MSP의 정의와 등장 배경
국제 MSP협회(www.mspassociation.org)에 따르면 ‘MSP(Management Service Provider)는 네트워크를 이용하여 다수의 고객들에게 IT 기반구조의 관리를 대행해 주며, 주로 월 단위로 서비스 요금을 과금하는 서비스’로 정의하고 있다. 따라서, 일부 MSP는 기존의 네트워크 관리회사 또는 소프트웨어 공급업체가 자사의 상품, 솔루션 및 서비스를 서비스 제공자(Service Provider) 모델에 알맞도록 변형시켜 제공하는 형태이며, 기업의 네트워크 관리 또는 시스템 관리를 대행해주는 ASP(Application Service Provider)로 볼 수도 있다.
미국에서는 1999년 중반부터 MSP 서비스가 주목을 받기 시작했는데, 그 이유는 IDC나 ASP와 마찬가지로 기업의 IT 자원에 대한 관리를 아웃소싱함으로써, 기업의 역량을 핵심부분에 집중할 수 있기 때문이다. 물론, 전자상거래 및 웹 응용분야의 급격한 성장 및 이에 따른 숙련된 엔지니어 확보의 어려움, 그리고 점점 더 복잡해지는 IT 기반구조로 인한 관리부담의 증가 등도 비용절감 이외에 MSP나 IDC 선택을 고려하게 하는 주요 요인이라 할 수 있다.
SP(Service Provider)의 전성시대
MSP라는 용어의 등장으로 인해 기존에 익숙하던 ISP나 ASP에 또 하나의 SP가 등장한 꼴이 되었다. 그러나, ISP, ASP, MSP 이외에도 수많은 xSP들이 나타날 준비를 하고 있다. 그 중 몇몇을 살펴보면 다음과 같다.
ISP(Internet Service Provider), NSP(Network Service Provider), WSP(Web hosting Service Provider), ASP(Application Service Provider), HSP(Hosting Service Provider :IDC), SSP(Storage Service Provider), SSP(Security Service Provider), MSP(Managed Service Provider 또는 Management Service Provider), TSP(Technology Service Provider), CSP(Component Service Provider), FSP(Full Service Provider) 등이다.
이들에 대해 간략히 설명하자면, 이중 가장 먼저 소개된 ISP에서 NSP가 분화되었다고 볼 수 있는데, NSP는 한국통신, 데이콤, PSINet과 같이 기간통신사업자 혹은 대형 ISP로서 타 ISP들에게 국내 또는 국제 백본망을 제공해 주는 SP들이다.
MSP라는 용어의 등장으로 인해 기존에 익숙하던 ISP나 ASP에 또 하나의 SP가 등장한 꼴이 되었다. 그러나, ISP, ASP, MSP 이외에도 수많은 xSP들이 나타날 준비를 하고 있다. 그 중 몇몇을 살펴보면 다음과 같다.
ISP(Internet Service Provider), NSP(Network Service Provider), WSP(Web hosting Service Provider), ASP(Application Service Provider), HSP(Hosting Service Provider :IDC), SSP(Storage Service Provider), SSP(Security Service Provider), MSP(Managed Service Provider 또는 Management Service Provider), TSP(Technology Service Provider), CSP(Component Service Provider), FSP(Full Service Provider) 등이다.
이들에 대해 간략히 설명하자면, 이중 가장 먼저 소개된 ISP에서 NSP가 분화되었다고 볼 수 있는데, NSP는 한국통신, 데이콤, PSINet과 같이 기간통신사업자 혹은 대형 ISP로서 타 ISP들에게 국내 또는 국제 백본망을 제공해 주는 SP들이다.
2024년 9월 22일 일요일
Advanced Kafka Configuration Important parameters to be aware of
1. auto.create.topics.enable=true => set to false in production
2. background.threads=10 => increase if you have a good CPU
3. delete.topic.enable=false => your choice
4. log.flush.interval.messages => don't ever change. Let your OS do it
5. log.retention.hours=168 => Set in regards to your requirements
6. message.max.bytes=1000012 => increase if you need more than 1MB
7. min.insync.replicas=1 => set to 2 fi you want to be extra safe
8. num.ios.threads=8 => ++if your network io is a bottleneck
9. num.network.threads=3 => ++if your network is a bottleneck
10. num.recovery.threads.per.data.dir=1 => set to number of disks
11. num.replica.fetchers=1 => increase if your replicas are lagging
12. offsets.retention.minutes=1440 => after 24 hours you lose offsets
13. unclean.leader.election.enable=true => false if you don't want data loss
14. zookeeper.session.timeout.ms=6000 => increase if you timeout often
15. broker.rack=null => set your to availability zone in AWS
16. default.replication.factor=1 => set to 2 or 3 in a kafka cluster
17. num.partitions=1 => set from 3 to 6 in your cluster
18. quota.producer.default=10485760 => set quota to 10MBs
19. quota.consumer.default=10485760 => set quota to 10MBs
2024년 9월 21일 토요일
How to change a Kafka configuration
1. Change the configuration on every file server.properties
2. Proceed to a rolling restart of all the brokers
#!/bin/bash
# let's apply a new setting to our server.properties
pwd
# make sure you're in the /home/ubuntu/kafka directory
cat config/server.properties
echo "unclean.leader.election.enable=false" >> config/server.properties
cat config/server.properties
# look at the logs - what was the value before?
cat logs/server.log | grep unclean.leader
# stop the broker
sudo service kafka stop
# restart the broker
sudo service kafka start
# look at the logs - what is the value after?
cat logs/server.log | grep unclean.leader
# operate on the three brokers
Running Kafka on AWS in Production
1. Separate your instances between different availability zones
2. Use stl EBS volumes for the best price / performance ratio
3. Use r4.xlarge or m4.2xlarge if you're using EBS(these instances are EBS optimized). You can use something smaller but performance may degrade
4. Setup DNS names for your brokers / fixed IPs so that your clients aren't affected if you recycle your EC2 instances
Factors impacting Kafka performance Other
1. Make sure you have enough file handles opened on your servers, as Kafka opens 3 file descriptor for each topic-partition-segment that lives on the Broker.
2. Make suer you use Java 8
3. You may want to tune the GC implementation: (see in the resources)
4. Set Kafka quatas in order to prevent unexpected spikes in usage
Factors impacting Kafka performance Operating System(OS)
1. Use Linux or Solaris, running production Kafka clusters on Windows is not recommended.
2. Increase the file descriptor limits (at least 100,000 as a starting point)
https://unix.stackexchange.com/questions/8945/how-can-i-increase-open-files-limit-for-all-processes/8949#8949
3. Make sure only Kafka is running on your Operating System. Anything else will just slow the machine down.
Factors impacting Kafka performance CPU
1. CPU is usually not a performance bottle neck in Kafka because Kafka does not parse any messages, but can become one in some situations
2. If you have SSL enabled, Kafka has to encrypt and decrypt every payload, which adds load on the CPU
3. Compression can be CPU bound if you force Kafka to do it. Instead, if you send compressed data, make sure your producer and consumers are the ones doing the compression work (that's the default setting anyway)
4. Make sure you monitor Garbage Collection over time to ensure the pauses are not too long
2024년 9월 13일 금요일
Factors impacting Kafka performance RAM
1. Kafka has amazing performance thanks to the page cache which utilizes your RAM
2. Understanding RAM in Kafka means understanding two parts:
- The Java HEAP from the Kafka process
- The rest of the RAM used by the OS page cache
3. Let's understand how both of those should be sized
4. Overall, your Kafka production machines should have at least 8GB of RAM to them(the more the better - it's common to have 16GB or 32GB per broker)



* Java Heap
5. When you launch Kafka, you specify Kafka Heap Options(KAFKA_HEAP_OPTS environment variable)
6. I recommend to assign a MAX amount (-Xms) of 4GB to get started to the kafka heap:
7. export KAFKA_HEAP_OPTS="-Xmx4g"
8. Don't set -Xms (starting heap size):
- Ket heap grow over time
- Monitor the heap over time to see if you need to increases Xmx
9. Kafka should keep a low heap usage over time, and heap should increase only if you have more partitiions in your broker
* OS Page Cache
10. The remaining RAM will be used automatically for the Linux OS Page Cache.
11. This is used to buffer data to the disk and this is what gives Kafka an amazing performance
12. You don't have to specify anything!
13. Any un-used memory will automatically be leveraged by the Linux Operating System and assign memory to the page cache
14. Note: Make sure swapping is disabled for Kafka entirely
vm.swappiness=0 or vm.swappiness=1(default is 60 on Linux)
Factors impacting Kafka performance Network
1. Latency is key in Kafka
- Ensure your Kafka instances are your Zookeeper instances are geographically close!!!
- Do not put one broker in Europe and the other broker in the US
- Having two brokers live on the same rack is good for performance, but a big risk if the rack goes down.
2. Network bandwidth is key in Kafka
- Network will be your bottleneck.
- Make sure you have enough bandwidth to handle manyu connections, and TCP requests.
- Make sure your network is high performance
3. Monitor network usage to understand when it becomes a bottleneck
2024년 9월 12일 목요일
Factors impacting Kafka performance
1. Reads are done sequentially (as in not randomly), therefore make sure you should a disk type that corresponds well to the requirements
2. Format your drives as XFS(easiest, no tuning required)
3. If read/write throughput is your bottleneck
- it is possible to mount multiple disks in parallel for Kafka
- The config is log.dirs=/disk1/kafka-logs, /disk2/kafka-logs,/disk3/kafka-logs...
4. Kafka performance is constant with regards to the amount of data stored in Kafka.
- Make sure you expire data fast enough (default is one week)
- Make sure you monitor disk performance
Hands On: Demonstrating Kafka resiliency
1. We create a topic with 3 as a replication factor
2. We will start producing data consistently to a topic
3. We will read that data from a topic
4. We will kill one Kafka instance
5. We will kill another Kafka instance
6. We will kill the last Kafka instance

#!/bin/bash
# create a topic with replication factor of 3
bin/kafka-topics.sh --zookeeper zookeeper1:2181,zookeeper2:2181,zookeeper3:2181/kafka --create --topic fourth_topic --replication-factor 3 --partitions 3
# generate 10KB of random data
base64 /dev/urandom | head -c 10000 | egrep -ao "\w" | tr -d '\n' > file10KB.txt
# in a new shell: start a continuous random producer
bin/kafka-producer-perf-test.sh --topic fourth_topic --num-records 10000 --throughput 10 --payload-file file10KB.txt --producer-props acks=1 bootstrap.servers=kafka1:9092,kafka2:9092,kafka3:9092 --payload-delimiter A
# in a new shell: start a consumer
bin/kafka-console-consumer.sh --bootstrap-server kafka1:9092,kafka2:9092,kafka3:9092 --topic fourth_topic
# kill one kafka server - all should be fine
# kill another kafka server -
# kill the last server
# start back the servers one by one
# ERRORS:
# PRODUCER:
# org.apache.kafka.common.errors.TimeoutException: Expiring 137 record(s) for fourth_topic-0: 30024 ms has passed since batch creation plus linger time
# [2017-05-25 10:24:23,784] WARN Error while fetching metadata with correlation id 1086 : {fourth_topic=INVALID_REPLICATION_FACTOR} (org.apache.kafka.clients.NetworkClient)
# org.apache.kafka.common.errors.UnknownTopicOrPartitionException: This server does not host this topic-partition.
# [2017-05-25 10:24:23,850] WARN Received unknown topic or partition error in produce request on partition fourth_topic-0. The topic/partition may not exist or the user may not have Describe access to it (org.apache.kafka.clients.producer.internals.Sender)
# [2017-05-25 10:24:23,914] WARN Error while fetching metadata with correlation id 1092 : {fourth_topic=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
# org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
# CONSUMER:
# [2017-05-25 10:24:23,798] WARN Error while fetching metadata with correlation id 3431 : {fourth_topic=INVALID_REPLICATION_FACTOR} (org.apache.kafka.clients.NetworkClient)
# [2017-05-25 10:24:24,081] WARN Auto-commit of offsets {fourth_topic-0=OffsetAndMetadata{offset=3948, metadata=''}} failed for group console-consumer-25246: Offset commit failed with a retriable exception. You should retry committing offsets. (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator)
# [2017-05-25 10:24:24,231] WARN Received unknown topic or partition error in fetch for partition fourth_topic-0. The topic/partition may not exist or the user may not have Describe access to it (org.apache.kafka.clients.consumer.internals.Fetcher)









피드 구독하기:
덧글 (Atom)