- Example of Topic-A with 3 partitions
- Example of Topic-B with 2 partitions
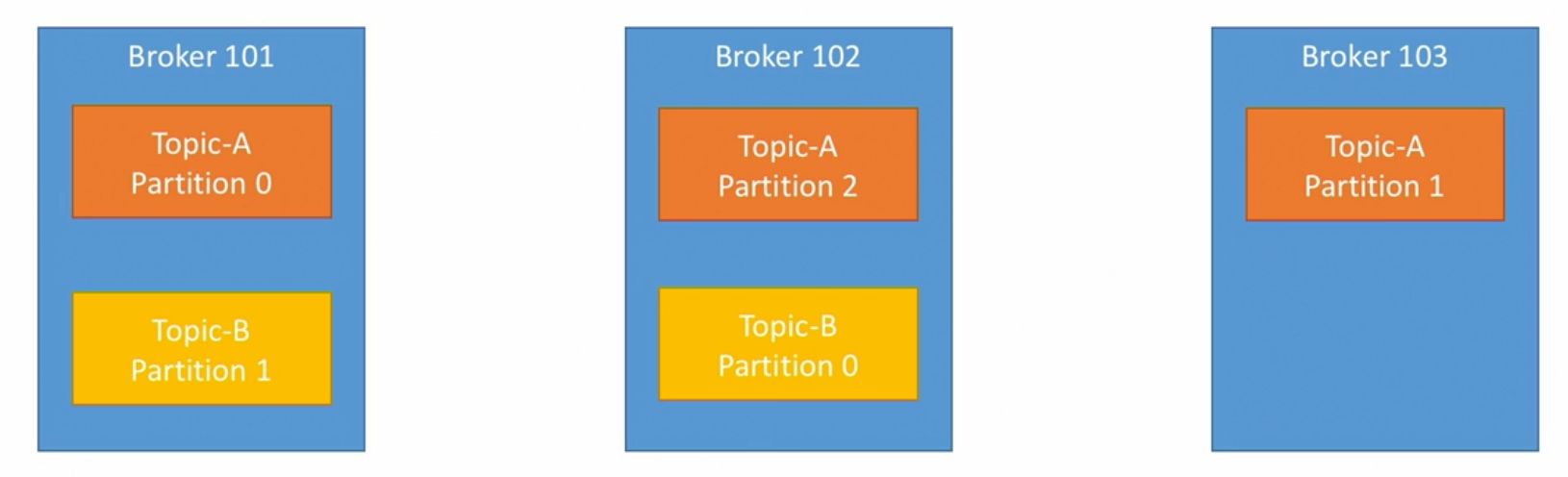
- Note: Data is distributed and Broker 103 doesn't have any Topic B data
- Example of Topic-A with 3 partitions
- Example of Topic-B with 2 partitions
- Note: Data is distributed and Broker 103 doesn't have any Topic B data
- A Kafka cluster is composed of multiple brokers(servers)
- Each broker is identified with its ID(integer)
- Each broker contains certain topic partitions
- After connectiong to any broker (called a bootstrap broker), you will be connected to the entire cluster
- A good number to get started is 3 brokers, but some big clusters have over 100 brokers
- In these examples we choose to number brokers starting at 100(arbitrary)

- Topics: a particular stream of data
1) Similar to a table in a database(without all the constraints)
2) You can have as many topics as you want
3) A topic is identified by its name
- Topics are split in partitions
1) Each partition is orderd
2) Each message within a partition gets an incremental id, called offet

- E.g. offset 3 in partition 0 doesn't represent the same data as offset 3 in partition 1
- Order is guaranteed only within a partition (not across partitions)
- Data is kept only for a limited time (default is noe week)
- Once the data is written to a partition, it can't be changed (immutability)
- Data is assigned randomly to a partition unless a key is provided (more on this later)

- Say you have a fleet of trucks, each truck reports its GPS position to Kaflk.
- You can have a topic trucks_gps that contains the position of all trucks.
- Each truck will send a message to Kafka every 20 seconds, each message will contain the truck ID and the truck position (latitude and longitude
- We choose to create that topic with 10 partitions(arbitrary number)
- Netflix uses Kafka to apply recommendations in real-time while you're watching TV shows
- Uber uses Kafka to gather user, taxi and trip data in real-time to compute and forecast demand, and compute surge pricing in real-time
-LinkedIn uses Kafka to prevent spam, collect user interactgions to make better connection recommendations in real time.
-Remember that Kafka is only used as a transportation mechanism!
- Messaging System
- Activity Tracking
- Gather metrics from many different locations
- Application Logs gathering
- Stream processing(with the Kafka Streams API or Spark for example)
- De-coupling of system dependencies
- Integration with Spark, Flink, Storm, Hadoop, and many other Big Data technologies
- Created by LinkedIn, now Open Source Project mainly maintained by Confluent
- Distributed, resilient architecture, fault tolerant
- Horizontal scalability:
1) Can scale to 100s of brokers
2) Can scale to millions of messages per second
- High performance (latency of less than 10ms) - real time
- Used by the 2000+ firms, 35% of the Fortune 500: