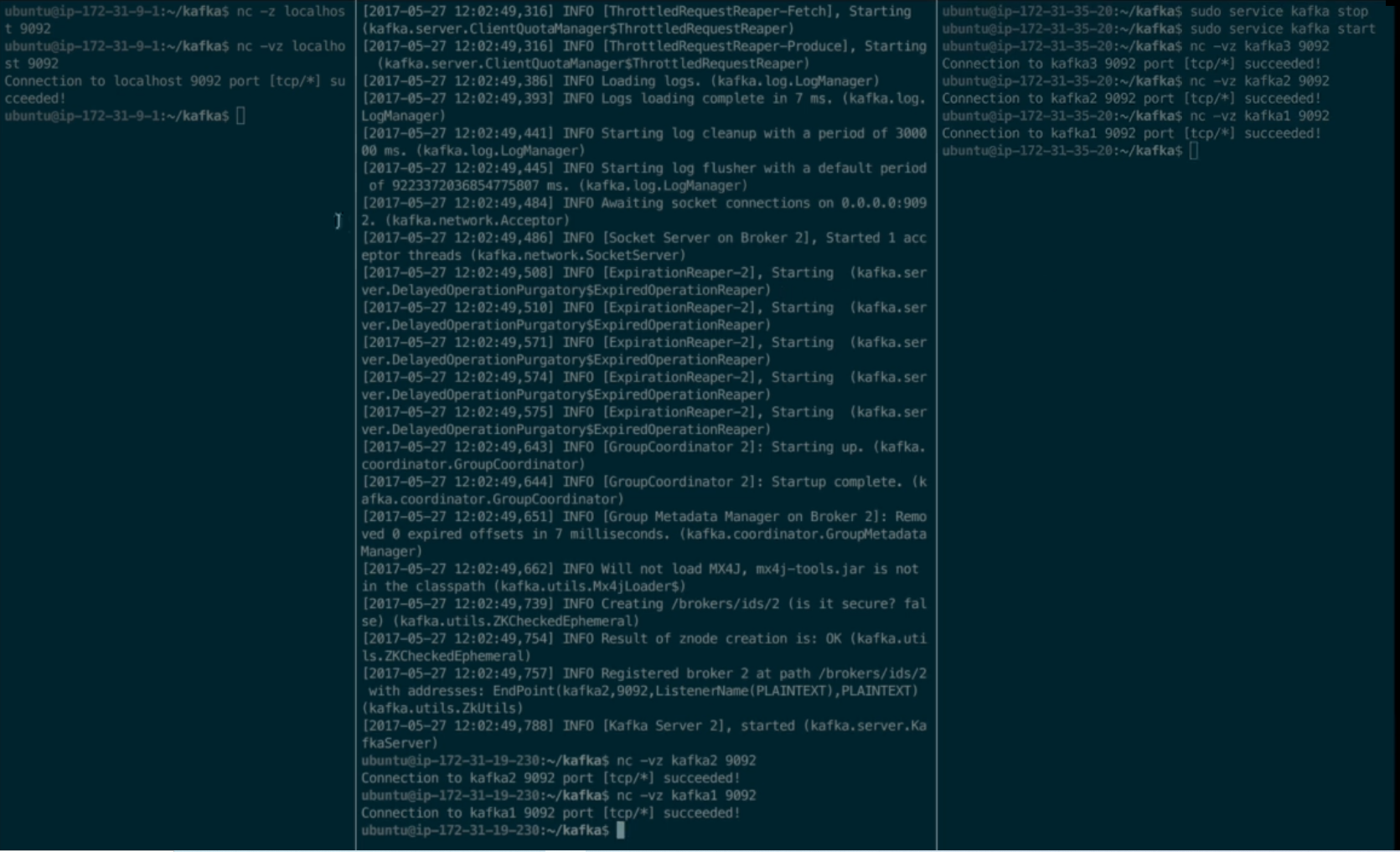
1. Configuring Kafka in production is an ART.
2. It requires really good understanding of:
- Operation Systems Architecture
- Servers Architecture
- Distributed Computing
- CPU operations
- Network performance
- Disk I/O
- RAM and Heap size
- Page cache
- Kafka and Zookeeper
3. There are over 140 configuration parameters available for Kafka
- Only a few parameters are needed to get started
- Importance is classified between mandatory, high, medium and low.
- I have deployed Kafka where more than 40 parameters are in use
4. You will never get the optimal configuration right for your needs the first time
5. Configuring Kafka is an iterative process: behavior changes over time based on usage and monitoring, so should your configuration
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
# change your.host.name by your machine's IP or hostname
advertised.listeners=PLAINTEXT://kafka1:9092
# Switch to enable topic deletion or not, default value is false
delete.topic.enable=true
############################# Log Basics #############################
# A comma seperated list of directories under which to store log files
log.dirs=/data/kafka
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=8
# we will have 3 brokers so the default replication factor should be 2 or 3
default.replication.factor=3
# number of ISR to have in order to minimize data loss
min.insync.replicas=2
############################# Log Retention Policy #############################
# The minimum age of a log file to be eligible for deletion due to age
# this will delete data after a week
log.retention.hours=168
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=zookeeper1:2181,zookeeper2:2181,zookeeper3:2181/kafka
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
############################## Other ##################################
# I recommend you set this to false in production.
# We'll keep it as true for the course
auto.create.topics.enable=true